第6章 ベイズ統計
ベイズの定理で導かれる事後確率 $P(B_{i}|A)$ (ここでは $\pi_{2}(B_{i}|A)$ で表す) を使うのがベイズ統計学である. これは,事象 $A$ という客観的事実と事象 $B_{i}$ の主観的確率より導かれた確率であり, 現時点では,主観性と客観性の両方を扱える唯一の統計手法である. 一方,古典的統計学では実データしか扱えない. 実データ主義の強い統計的品質管理では,古典的統計学しか用いていないが, 近年は,品質の確率分布を予測する手段としてベイズ統計を利用するケースもでてきた. そこで,ベイズ統計学の考え方を解説する. なお,ベイズ統計学では尤度の概念が難しいので,そこに注意してほしい.6.1 基礎知識
確率は,以下の3種類に分類できる.- 理論的確率:サイコロの目など,理論的に求めることができる確率
- 客観的確率:実際のデータに基づいて計算される確率
- 主観的確率:経験や実績から設定される確率.例えば競馬のオッズ比など
確率の乗法定理
$P(A \cap B_{i})$ :事象 $A$ と事象 $B_{i}$ が同時に起こる確率(同時確率)$P(A | B_{i})$ :事象 $B_{i}$ の下で事象 $A$ が起こる確率(条件付き確率)
このとき,式(\ref{Bays_eq1})が成立する. \begin{equation} P(A \cap B_{i}) = P(B_{i} | A)P(A) = P(A | B_{i})P(B_{i}) \label{Bays_eq1} \end{equation}
ベイズの定理
$\sum_{i=1}^{n}P(B_{i})=1$ のとき,確率の乗法定理により式(\ref{Bays_eq2})が得られる. \begin{equation} P(B_{i}|A) = \frac{P(A|B_{i})P(B_{i})}{P(A)} = \frac{P(A|B_{i})P(B_{i})}{\sum_{i=1}^{n}P(A|B_{i})P(B_{i})} \label{Bays_eq2} \end{equation} ここで$P(B_{i})$ :事前確率.$\pi_{1}(B_{i})$ で表してもよい
$P(B_{i}|A)$ :事象 $A$ が起きた条件下で事象 $B_{i}$ が起きる事後確率.$\pi_{2}(B_{i}|A)$ で表してもよい
$P(A|B_{i})$ :事象 $B_{i}$ が起きた条件下で事象 $A$ が起きる確率.$f(A|B_{i})$ で表してもよい
:事象 $A$ が起きたときに事象 $B=B_{i}$ である尤度 $\ L(B_{i}|A)=f(A|B_{i})$ でもある.
6.2 確率分布予測例の紹介
簡単な2つの例題を用いて,ベイズ統計学の確率分布予測を説明する. 例1は事象が2つしかない離散的事象の問題である. 数式に積分が含まれないので分り易い. 一方,例2は事象が無限にある連続的事象の問題である. 現実の問題はこのタイプが多い.例1:離散型事象の確率分布予測
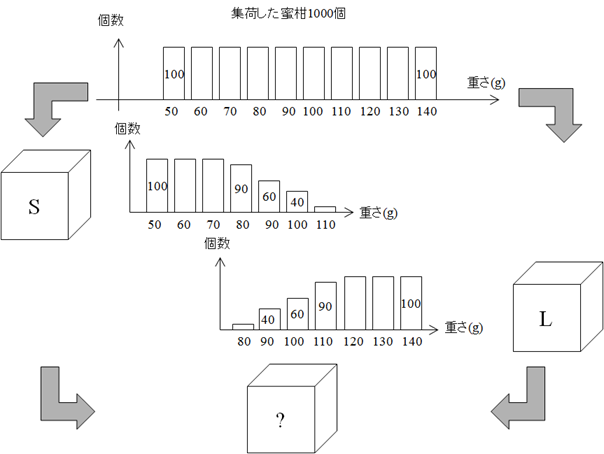
集荷場には1000個のみかんがあり, その重さは50g台~140g台まで100個ずつ分布していた. これらのみかんを大小に分別して2つの箱SとLに500個ずつ梱包した. このとき,SとLに入っているみかんの重さの分布は50g台~70g台のものはすべて箱Sに, 120g台~140g台のものはすべて箱Lに入っていたが,80g台~130g台は箱SとLの両方に分かれていた. その様子を表6.1と図6.1に示す.| みかんの重さ $x$ (g) | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | 140 |
|---|---|---|---|---|---|---|---|---|---|---|
| S | 100 | 100 | 100 | 90 | 60 | 40 | 10 | 0 | 0 | 0 |
| L | 0 | 0 | 0 | 10 | 40 | 60 | 90 | 100 | 100 | 100 |
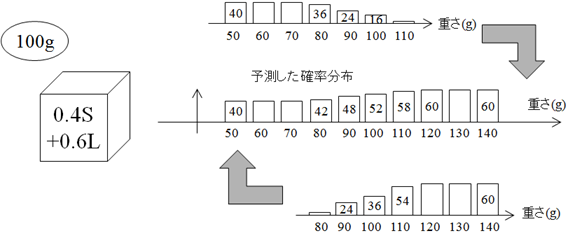
今,目の前にある箱の中にある蜜柑の重さ分布を予測したいのだが,箱がSかLか分らない. 何も情報が無い状態では,SあるいはLの箱を選択する事前確率 $\pi_{1}(S)$ と $\pi_{1}(L)$ は理論的に各々0.5である. ところで,各箱に入っている蜜柑の重さ $x$ の確率分布 $f(x|S)$ と $f(x|L)$ は 表6.1の値を個数で除したものになるから,表6.2になる. ここで,各箱に入っている蜜柑の重さの確率 $f(x|S)$ と $f(x|L)$ は,その箱がSまたはLである尤度でもある.
| みかんの重さ $x$ (g) | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | 140 |
|---|---|---|---|---|---|---|---|---|---|---|
| x|S | 0.20 | 0.20 | 0.20 | 0.18 | 0.12 | 0.08 | 0.02 | 0.00 | 0.00 | 0.00 |
| x|L | 0.00 | 0.00 | 0.00 | 0.02 | 0.08 | 0.12 | 0.18 | 0.20 | 0.20 | 0.20 |
よって,箱に入っている重さ $x$ のみかんの数 $n(x)$ は式(\ref{Bays_eq3})で予測される \begin{align} n(x) &= 500\times \{f(x|S)\pi_{1}(S)+f(x|L)\pi_{1}(L)\} \notag\\ &= 500\times \{f(x|S) \times 0.5+f(x|L) \times 0.5\} \label{Bays_eq3} \end{align} これを図6.2に示す.
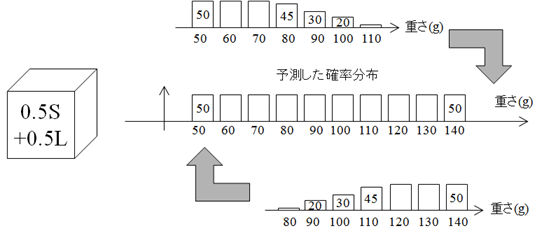
実際に計算すると,表6.3のように分布していると予想される. つまり,みかんを取り出す前は,どちらの箱の重さ分布も等しく考えていることになる.
| みかんの重さ $x$ (g) | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | 140 |
|---|---|---|---|---|---|---|---|---|---|---|
| 個数 $n(x)$ | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 | 50 |
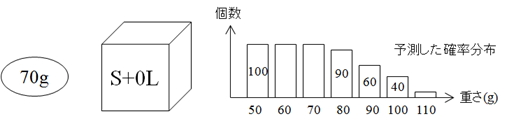
次に,箱から1つだけ取り出したみかんの重さが $w$ であったとすれば, 箱に入っている重さ $x$ のみかんの数 $n(x)$ は次式で予測される. \begin{equation} n(x) = 500\times \{f(x|S)\pi_{2}(S|w)+f(x|L)\pi_{2}(L|w)\} \label{Bays_eq4} \end{equation} このとき,事後確率 $\pi_{2}(S|w)$ と $\pi_{2}(L|w)$ は,ベイズの定理(式(\ref{Bays_eq2}))から得られる. \begin{equation} \pi_{2}(S|w) = \frac{f(w|S)\pi_{1}(S)}{f(w|S)\pi_{1}(S)+f(w|L)\pi_{1}(L)} \label{Bays_eq5} \end{equation} \begin{equation} \pi_{2}(L|w) = \frac{f(w|L)\pi_{1}(L)}{f(w|S)\pi_{1}(S)+f(w|L)\pi_{1}(L)} \label{Bays_eq6} \end{equation} いま,取り出したみかんが70gだったとき,各箱から70gの重さのみかんを取り出す確率(尤度)を考える. 70gのみかんは箱 $S$ にしか入っていないので,みかんを取り出した箱が $S$ であることは疑う余地がない. 一方,70gのみかんを取り出した箱が $S$ あるいは $L$ である事後確率 $\pi_{2}$ は 式(\ref{Bays_eq5}),(\ref{Bays_eq6})を用いて計算することができる. 実際,表6.3から,箱 $S$ と箱 $L$ の各々から70gのみかんを取り出す確率 $f(70g|S)$ と $f(70g|L)$ を求め, 式(\ref{Bays_eq5}),(\ref{Bays_eq6})に代入すれば,式(\ref{Bays_eq7}),(\ref{Bays_eq8})を得る. \begin{equation} \pi_{2}(S|70) = \frac{f(70|S)\pi_{1}(S)}{f(70|S)\pi_{1}(S)+f(70|L)\pi_{1}(L)} = \frac{0.2 \times 0.5}{0.2 \times 0.5 + 0 \times 0.5} = 1 \label{Bays_eq7} \end{equation} \begin{equation} \pi_{2}(L|70) = \frac{f(70|L)\pi_{1}(L)}{f(70|S)\pi_{1}(S)+f(70|L)\pi_{1}(L)} = \frac{0 \times 0.5}{0.2 \times 0.5 + 0 \times 0.5} = 0 \label{Bays_eq8} \end{equation} これは,至極当たり前の結果であるが, ベイズ統計の方法では,当たり前のことを当たり前の形で予測できていることが分かる. この場合,箱に入っている重さ $x$ のみかんの数 $n(x)$ は式(\ref{Bays_eq9})で予測される. \begin{align} n(x) &= 500\times \{f(x|S)\pi_{2}(S|70)+f(x|L)\pi_{2}(L|70)\} \notag\\ &= 500\times f(x|S) \label{Bays_eq9} \end{align} 式(\ref{Bays_eq9})から求められるみかんの重さの予測分布は,図6.3のようになる. このとき,$f(x|S)$ と $f(x|L)$ は各箱における蜜柑の重さの確率分布であると同時に,各箱の尤度でもある.
ところで,取り出したみかんが100gだったとする. このときも,各箱から100gの重さのみかんを取り出す尤度は表6.3から分かる. 箱$S$が0.08,箱$L$が0.12であるから,100gの重さのみかんを取り出した箱が$S$である確率は 0.4,$L$である確率は0.6となる. これは,箱$S$と箱$L$の各々から100gのみかんを取り出す確率と等しい. 表6.3から,尤度を式(\ref{Bays_eq5}),(\ref{Bays_eq6})に代入すれば, 式(\ref{Bays_eq10}),(\ref{Bays_eq11})を得る. \begin{equation} \pi_{2}(S|100) = \frac{f(100|S)\pi_{1}(S)}{f(100|S)\pi_{1}(S)+f(100|L)\pi_{1}(L)} = \frac{0.08 \times 0.5}{0.08 \times 0.5 + 0.12 \times 0.5} = 0.4 \label{Bays_eq10} \end{equation} \begin{equation} \pi_{2}(L|100) = \frac{f(100|L)\pi_{1}(L)}{f(100|S)\pi_{1}(S)+f(100|L)\pi_{1}(L)} = \frac{0.12 \times 0.5}{0.08 \times 0.5 + 0.12 \times 0.5} = 0.6 \label{Bays_eq11} \end{equation} よって,箱に入っている重さ$x$のみかんは式(\ref{Bays_eq12})で予測される. \begin{eqnarray} n(x) &= 500\times \{f(x|S)\pi_{2}(S|100)+f(x|L)\pi_{2}(L|100)\} \notag\\ &= 500\times \{f(x|S)\times 0.4+f(x|L)\times 0.6\} \label{Bays_eq12} \end{eqnarray} 式(\ref{Bays_eq12})から予測される分布は,表6.4,図6.4のようになる.
| みかんの重さ$x$(g) | 50 | 60 | 70 | 80 | 90 | 100 | 110 | 120 | 130 | 140 |
|---|---|---|---|---|---|---|---|---|---|---|
| 個数$n(x|100)$ | 40 | 40 | 40 | 42 | 48 | 52 | 58 | 60 | 60 | 60 |